 Nos cours en ligne
Nos cours en ligne 
'%3e%3cpath%20d='M50.2142%2018.9386C49.891%2017.9389%2049.0043%2017.2289%2047.9552%2017.1343L33.7053%2015.8404L28.0704%202.65157C27.655%201.685%2026.7087%201.05933%2025.6574%201.05933C24.6061%201.05933%2023.6599%201.685%2023.2444%202.65383L17.6096%2015.8404L3.35734%2017.1343C2.31016%2017.2311%201.42571%2017.9389%201.10063%2018.9386C0.775554%2019.9383%201.07577%2021.0349%201.86794%2021.7261L12.6392%2031.1726L9.46301%2045.1637C9.2306%2046.1924%209.62988%2047.2558%2010.4834%2047.8728C10.9423%2048.2043%2011.479%2048.3731%2012.0203%2048.3731C12.487%2048.3731%2012.95%2048.2473%2013.3655%2047.9986L25.6574%2040.6522L37.9448%2047.9986C38.844%2048.5396%2039.9774%2048.4902%2040.8291%2047.8728C41.683%2047.2539%2042.0819%2046.1902%2041.8495%2045.1637L38.6733%2031.1726L49.4446%2021.728C50.2368%2021.0349%2050.5393%2019.9402%2050.2142%2018.9386Z'%20fill='%23FFC107'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1229_10547'%3e%3crect%20width='49.3714'%20height='49.3714'%20fill='white'%20transform='translate(0.971436)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) 4,8 en moyenne
4,8 en moyenne
Qu'est-ce qu'un captcha ?
L'origine, l'histoire et le fonctionnement des systèmes de captcha au fur et à mesure de l'histoire du web !

Article publié le 31/07/2023, dernière mise à jour le 19/09/2023
Un captcha est un système automatisé pour différencier les humains des robots sur internet, principalement afin d'éviter de retrouver les contenus de son site spammés de liens en tous genres.
Le mot "CAPTCHA" est une déformation du mot "capture" en anglais, et il est parfois considéré comme un acronyme pour "Completely Automated Public Turing test to tell Computers and Humans Apart".
En réalité, l'acronyme est arrivé après la création de la marque "CAPTCHA", déposée par l'université Carnegie-Mellon, Pennsylvannie.
Pour faire court : Un captcha est un widget qui doit pouvoir être résolu par un humain, mais pas par une machine.
Invention
Le concept de détection des humains est théorisé dès 1996 et implémenté pour la première fois en 1997 par AltaVista, afin d'éviter les demandes d'indexation de certains sites web sur le moteur de recherche par des robots.

Exemple de captcha AltaVista
Comme toute technologie censée protéger un système, cette dernière va devoir rentrer en compétition féroce avec tous les systèmes développés pour la contourner ou passer au travers.
C'est que l'on appelle, en sécurité, le jeu du chat et de la souris !
Et plus la technologie devient puissante, plus il est difficile de trouver des parades. Pendant plus de dix ans les captcha vont évoluer, en obligeant les utilisateurs à :
- Résoudre des opérations mathématiques
- Retranscrire un mot dans un fichier audio
- Reconnaître des caractères dans des images brouillées
- etc...
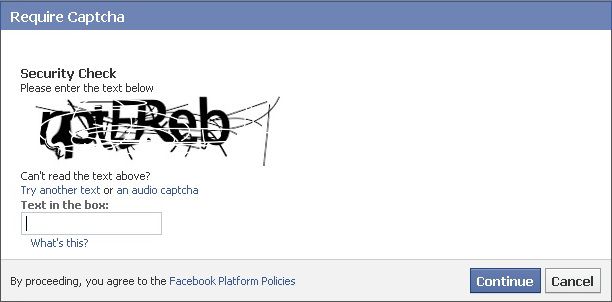
L'un des plus gros contributeurs à ces évolutions sera Yahoo, qui fera tout pour éviter la pollution de ses "salons de discussions" par des robots postant des messages promotionnels.
Toutes les entreprises développent leurs propres systèmes, jusqu'à ce que...
Révolution
C'est en 2009, avec leur système intitulé "reCaptcha", que 7 chercheurs de l'université Carnegie-Mellon vont révolutionner le monde de la vérification des humains vs robots dans le monde numérique.
Le concept : Utiliser des archives (livres et articles) et les intégrer à un service de captcha classique pour numériser ces écrits papiers.
C'est ce que l'on appelle du "crowdsourcing implicite"
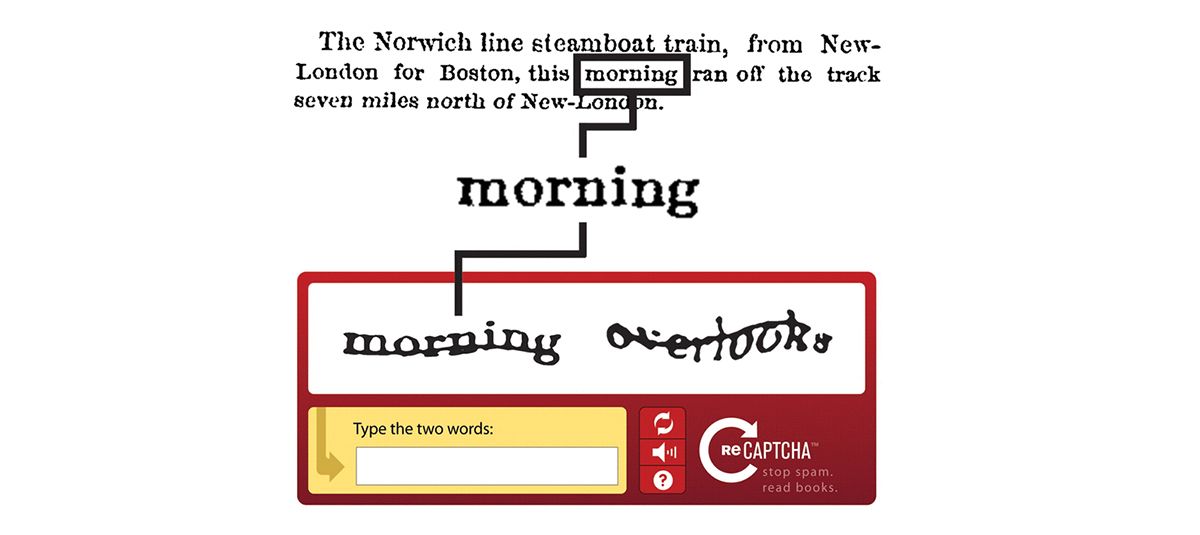
À chaque fois, reCaptcha va proposer deux mots : l'un déjà numérisé, et l'autre non.
Le premier mot va servir à départager les humains et les machines, et l'autre va servir à avancer la numérisation des archives. Parmi toutes les réponses pour le deuxième mot, il y aura un arbitrage automatique sur toutes les réponses fournies par les utilisateurs.
C'est la première fois qu'un service de captcha va rapporter de l'argent à une entreprise, au lieu d'en perdre (avec les coûts liés au service).
C'est ce qui va pousser l'entreprise à proposer ce service gratuitement à toutes les personnes et entreprises qui souhaitent intégrer ce plugin sur leur site, et c'est ce qui va permettre de réellement démocratiser les captcha sur le web.
En quelques mois, reCaptcha va être en mesure de numériser 20 ans d'archives du New York Times.
En Septembre 2009, Google rachète la société reCaptcha pour accélérer la numérisation de son service "Google Books".
Reconnaissance d'images
À partir de 2012, les algorithmes d'OCR (Optical Character Recognition) deviennent suffisamment efficaces pour que les Captcha à base de textes deviennent impuissants face à de nombreux robots.
Google va alors trouver une parade : utiliser des images issues de son service StreetView :
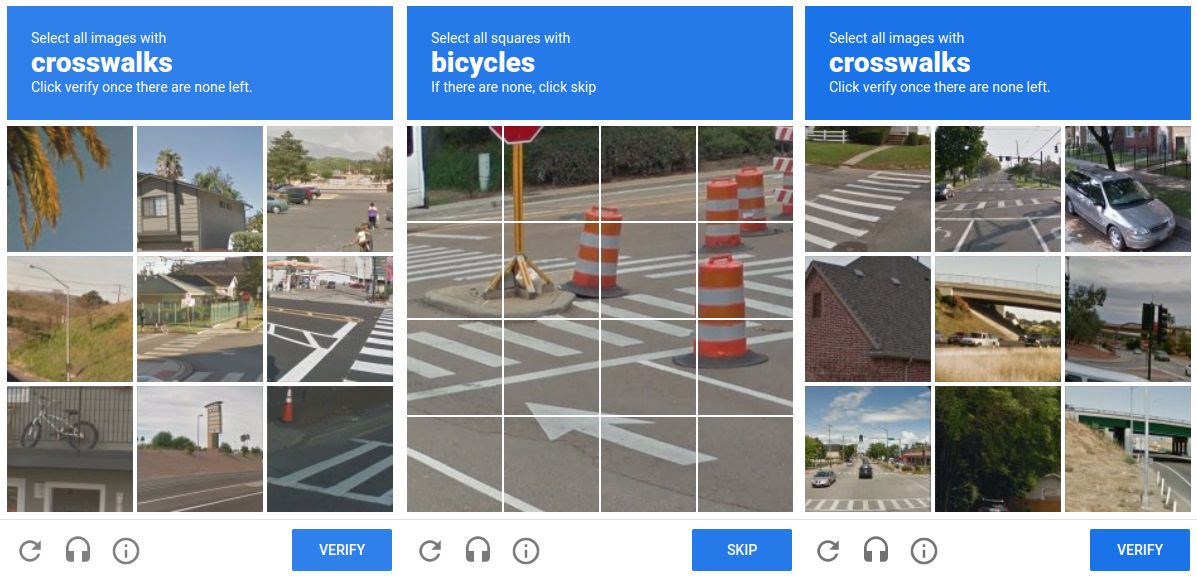
Les réponses des utilisateurs vont alors permettre à Google d'entrainer leurs propres algorithmes de reconnaissance d'images et d'objets sur des ensembles de données très fiables !
Cette méthode est beaucoup plus fiable pour filtrer les robots, mais également beaucoup plus chronophage pour les humains.
Google va donc adopter une méthode beaucoup plus rapide mais également... controversée...
Des captcha en un clic
Intégrer un service de captcha sur un site, c'est aussi intégrer un script tiers... Cela signifie que ce script aura accès à des informations préalablement stockés dans les cookies.
Comme par exemple un identifiant de session
Et c'est comme cela que Google a pu développer un service de captcha quasi-invisible :
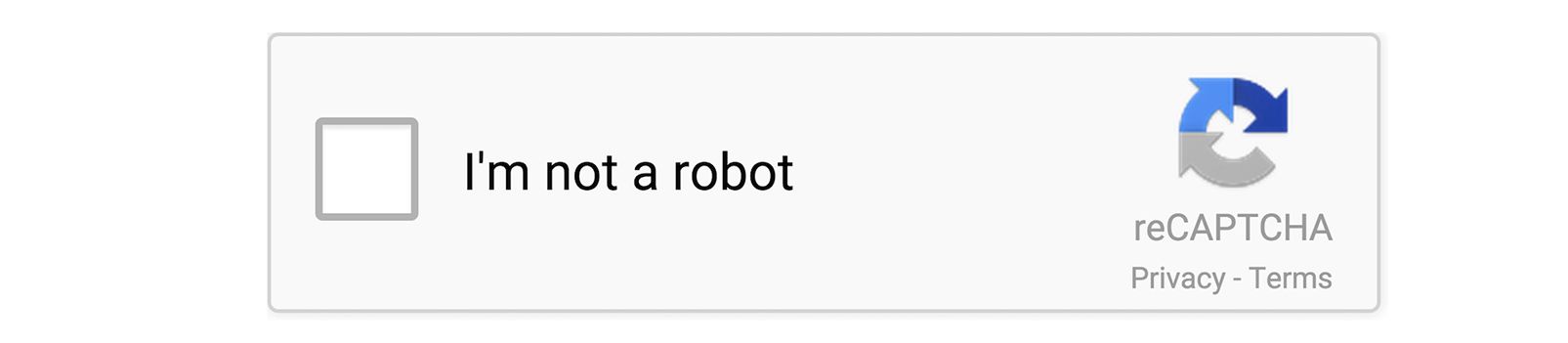
Ce captcha fonctionne en trois temps :
- Si Google possède assez d'informations sur l'utilisateur, alors le captcha sera invisible et est automatiquement validé
- Sinon, il suffira simplement de cocher une case, ce qui permettra au service de détecter le côté "humains" des mouvements de souris
- Si il y a encore un doute, Google affichera un test de reconnaissance d'images
Si cette solution parait moins contraignante pour les visiteurs, elle pose un réel problème en termes d'utilisation des données personnelles, et rentre en conflit avec la législation européenne et française.
Alternatives
Si vous cherchez à intégrer un système de prévention des robots sous la forme d'un captcha, mais avec un service respectueux des données personnelles (et efficace), vous pouvez tester le service hCaptcha, qui rempli tous les critères !
Et ne nécessite aucune déclaration RGPD supplémentaire.
Aucun commentaire pour l'instant