 Nos cours en ligne
Nos cours en ligne 
'%3e%3cpath%20d='M50.2142%2018.9386C49.891%2017.9389%2049.0043%2017.2289%2047.9552%2017.1343L33.7053%2015.8404L28.0704%202.65157C27.655%201.685%2026.7087%201.05933%2025.6574%201.05933C24.6061%201.05933%2023.6599%201.685%2023.2444%202.65383L17.6096%2015.8404L3.35734%2017.1343C2.31016%2017.2311%201.42571%2017.9389%201.10063%2018.9386C0.775554%2019.9383%201.07577%2021.0349%201.86794%2021.7261L12.6392%2031.1726L9.46301%2045.1637C9.2306%2046.1924%209.62988%2047.2558%2010.4834%2047.8728C10.9423%2048.2043%2011.479%2048.3731%2012.0203%2048.3731C12.487%2048.3731%2012.95%2048.2473%2013.3655%2047.9986L25.6574%2040.6522L37.9448%2047.9986C38.844%2048.5396%2039.9774%2048.4902%2040.8291%2047.8728C41.683%2047.2539%2042.0819%2046.1902%2041.8495%2045.1637L38.6733%2031.1726L49.4446%2021.728C50.2368%2021.0349%2050.5393%2019.9402%2050.2142%2018.9386Z'%20fill='%23FFC107'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1229_10547'%3e%3crect%20width='49.3714'%20height='49.3714'%20fill='white'%20transform='translate(0.971436)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) 4,8 en moyenne
4,8 en moyenne
Tutoriel : Créer un jeu d'aventure textuel en NodeJS (Partie 1)
Vous avez envie de créer un jeu vidéo mais vous n'avez pas le temps où les moyens de travailler sur les graphismes ? J'ai la solution !

Article publié le 04/09/2020, dernière mise à jour le 19/09/2023
Je suis né dans les années 90, et pourtant l'un des jeux vidéos m'ayant le plus marqué dans ma vie reste un jeu sorti dans les années 80 : Zork I.
Zork est un jeu d'aventure textuel dans lequel vous incarnez un personnage découvrant un passage sous une petite maison qui vous permettra notamment d'explorer des souterrains pleins de surprises.
Et oui, vous l'aurez deviner, il n'y a aucun graphisme, tout se passe en ligne de commande.
Pour les plus curieux, voici à quoi ressemble Zork, et maintenant vous pouvez même y jouer en ligne à cette adresse !
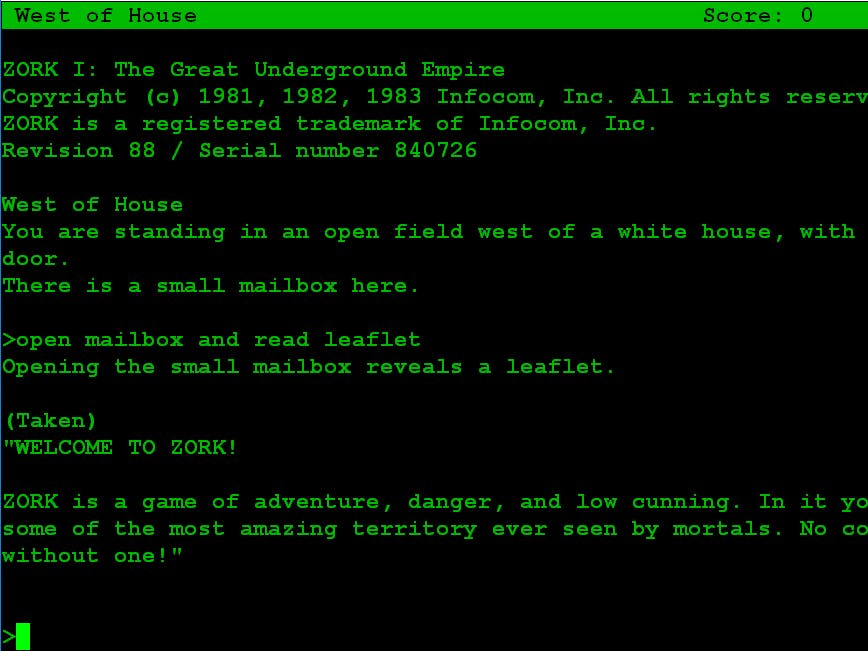
Même si le fait d'avoir à écrire pour effectuer des actions peut paraitre contre-intuitif, cela donne aussi une sensation de liberté et de possibilités presques infinies qui ne se limite pas à un quelconque nombre de boutons sur lesquels appuyer !
C'est d'ailleurs pour ça que j'avais évoqué cette idée dans mon article "9 idées de projets créatifs pour les développeurs web juniors" car il offre une grande liberté à construire, mais le moteur de jeu reste un challenge technique très intéressant, notamment au niveau du parser syntaxique qui doit pouvoir comprendre les phrases entrées par le joueur !
C'est donc par celà que je vais commencer pour vous guider au travers de la création d'un jeu d'aventure textuel dans la première partie de ce tutoriel dont vous pourrez retrouver l'entièreté du code sur Github !
Partie 1 : Le parser syntaxique
Que l'on soit d'accord, le but n'est bien sûr pas de créer un parser qui sera capable de détecter l'entièreté de la langue française, mais il aura deux objectifs :
- Comprendre suffisamment de termes pour lier toutes les fonctionnalités de notre futur jeu
- Être assez permissif pour ne pas compliquer la tâche au joueur
En clair, notre parser devra être capable de détecter des phrases comme "prendre", "prendre lettre", "prendre la lettre" ou encore "aller vers le nord", tout en refusant des phrases comme "je voudrais vraiment aller au nord de la colline" pour des raisons de simplicité !
Modélisation de la syntaxe
En prenant les exemple du dessus, on va devoir définir les différents types de mots présents dans la phrase, ainsi que leur ordre possible, c'est ce que l'on va appeler un "arbre syntaxique".
Le nôtre va donc contenir 4 types de mots différents : un verbe à l'infinitif (aller), une préposition (vers), un article (le) et un nom (nord). Mais attention, comme on a vu avant ils ne sont pas tous obligatoires, ce qui va nous donner comme possibilités :
- [VERBE, PREPOSITION, ARTICLE, NOM]
- [VERBE, ARTICLE, NOM]
- [VERBE, NOM]
- [VERBE]
Maintenant il ne nous reste plus qu'à créer notre classe Parser et à commencer à rentrer une collection de possibilités pour chacun des types de mots ci-dessus.
class Parser {
constructor(){
this.infinitive_verbs = [
"prendre",
"ouvrir",
"regarder",
"lire",
"aller",
"poser"
]
this.articles = [
"le",
"la",
"au"
];
this.prepositions = [
"vers",
"sur",
"dans"
]
this.nouns = [
"boite",
"lettre",
"nord",
"sud"
];
}
}
module.exports = Parser;
Les tokens
Une fois que nos différentes possibilités sont stockées (et facilement extensibles), il va nous falloir des méthodes afin de transformer les mots de notre phrases en "tokens".
La "tokenisation" d'une chaine de caractère consiste à découper cette chaine d'une certaine manière (ici on va séparer les mots entre chaque espace) pour venir ajouter de la donnée sur chacun de ces mots.
Ici le but va être d'ajouter le type de mot afin de pouvoir le classifier, et pour celà nous allons avoir besoin de petites fonctions qui vont simplement parcourir toutes les possibilités pour voir si le mot fourni correspond à l'une d'entre-elles.
Si oui, on va créer le token correspondant, sinon on renvoi la valeur null.
//File : Parser.js
INFINITIVE_VERB(word){
let result = this.infinitive_verbs.find((verb)=>{return verb === word.toLowerCase();});
return result ? {type: "verb", value: result} : null;
}
NOUN(word){
let result = this.nouns.find((noun)=>{return noun === word.toLowerCase();});
return result ? {type: "noun", value: result} : null;
}
ARTICLE(word){
let result = this.articles.find((article)=>{return article === word.toLowerCase();});
return result ? {type: "article", value: result} : null;
}
PREPOSITION(word){
let result = this.prepositions.find((preposition)=>{return preposition === word.toLowerCase();});
return result ? {type: "preposition", value: result} : null;
}
Parsing et parcours de l'arbre
Voici la dernière partie (et non des moindres) de notre parser. Son but est de parcourir chaque branche de l'arbre, et de tester chaque item de chaque branche pour détecter si la phrase est compatible avec l'une de ses branche afin de pouvoir transformer chaque mot en token.
//Parser.js
//Take a sentence a return the same sentence tokenized or throw an error
parseText(str){
//Initialize the token array and transform the string into an array or words
let tokens = [];
let str_array = str.split(' ');
//Let's build the syntaxic tree, from the longest possibility to the shortest (mandatory)
let syntaxic_tree = [
[this.INFINITIVE_VERB.bind(this),this.PREPOSITION.bind(this), this.ARTICLE.bind(this), this.NOUN.bind(this)],
[this.INFINITIVE_VERB.bind(this),this.ARTICLE.bind(this), this.NOUN.bind(this)],
[this.INFINITIVE_VERB.bind(this), this.NOUN.bind(this)],
[this.INFINITIVE_VERB.bind(this)]
];
//Let's try every possible sentence form until one succeed
let success = syntaxic_tree.some(function(syntaxic_branch){
//Let's copy all the words to avoid reference issues
let local_str_array = [...str_array];
let local_tokens = [];
//For every branch item, let's check if the next word (of first) fits a token type
let valid_syntax = syntaxic_branch.every(function(syntaxic_token){
let token = local_str_array[0] ? syntaxic_token(local_str_array[0].toLowerCase()) : null;
if(token){
//If the word fits a token, then we push the token and remove the word from the sentence
local_tokens.push(token);
local_str_array.splice(0,1);
return true;
}
return false;
});
//The sentence if fully parsed only when all the token has been found for a branch and there are no word remaining in the sentence
if(valid_syntax && local_str_array.length === 0){
tokens = local_tokens;
return true;
}
return false;
});
if(!success){
//If no branch of the syntaxic tree was compatible, the parsing couldn't be done
throw new Error("ParsingError");
}
return tokens;
}
Pour que celà soit plus clair, pour la phrase "Aller au nord", c'est la troisième branche de notre arbre qui sera compatible, soit [INFINITIVE_VERB, ARTICLE, NOUN] et la phrase ressortira sous la forme suivante :
[
{ type: 'verb', value: 'aller' },
{ type: 'article', value: 'au' },
{ type: 'noun', value: 'nord' }
]
Grâce à ces informations, il nous sera désormais facile de relier chaque mot de la phrase à une action à l'intérieur du jeu !
Les tests
Afin de tester différentes formes syntaxiques et de voir si le parser fonctionne correctement, j'ai créé un fichier index.js qui sert simplement à le lancer avec quelques phrases d'exemples.
const Parser = require('./Parser.js');
let parser = new Parser();
const sentences = [
"regarder",
"ouvrir",
"ouvre",
"prendre",
"lire",
"lire lettre",
"ouvrir boite",
"regarde boite",
"regarder la boite",
"aller au nord",
"aller vers le sud",
"sud aller vers le",
];
sentences.forEach((sentence)=>{
try {
let tokens = parser.parseText(sentence);
console.log(sentence, tokens);
} catch(e){
console.error("Invalid syntax for sentence: ",sentence);
}
});
Les résultats sortant du parser sont donc :
regarder [ { type: 'verb', value: 'regarder' } ]
ouvrir [ { type: 'verb', value: 'ouvrir' } ]
Invalid syntax for sentence: ouvre
prendre [ { type: 'verb', value: 'prendre' } ]
lire [ { type: 'verb', value: 'lire' } ]
lire lettre [ { type: 'verb', value: 'lire' }, { type: 'noun', value: 'lettre' } ]
...
N'oubliez pas que vous pouvez retrouver tout le code dans le dépôt Github ci-dessous !
 NicolasBrondin/line-adventure
NicolasBrondin/line-adventureLa suite
La partie 2 de ce tutoriel est disponible à cette adresse : https://blog.nicolas.brondin-bernard.com/blog/tutoriel-creer-un-jeu-daventure-textuel-en-nodejs-partie-2/
Aucun commentaire pour l'instant